
Services for Expert Identification
Purpose
Experts possess higher level of information and more context specific knowledge regarding a certain domain which differentiate them from amateurs. Often, they qualify to judge success of an approach, strategy or an activity. In general, expert identification is significant in informal learning environments: Firstly, experts affect on learning rate of novices and amateurs when they share their knowledge. Moreover, expertise of a person enhances the trustworthiness in resources, specifically, workplace learning requires the experience of such people. In fact, expertise contributes in engaging new connections and interactions among professionals and increasing trust. Therefore, we considered expert finding task in Learning Layers project. We implemented several algorithms to identify experts including community-aware ranking algorithms based on las2Peer. The aim of the Expert Identification Service (EIS) is to rank users based on their knowledge. In other words, EIS computes some reputation values for users and returns the list of top experts. Hence, users who need help can consider these calculated expertise when receiving an answer for a question. Moreover, it servers as a RESTful Web service and can be integrated with other analytic Web services such as overlapping community detection service.
Description
Research on Question-Answer forums can be categorized in three main branches including expert identification [1] [2], best answer identification [3] and retrieving of similar questions [4]. There is a large body of research on expert finding and the initial approaches focus on finding experts in corporations. Experts can be identified by combining self-reported directory information with keyword mining from user’s personal files and folders. Some other techniques consider expert finding task as a voting problem where documents vote for candidates with relevant expertise [5]. Modern approaches investigate corresponding social network related to experts. For instance, Bozzon et al. found corresponding profiles of workers in Facebook, LinkedIn and Twitter [6]. There have been other statistical approaches for expert finding; however, they have not considered the community dimension to identify experts. Researchers have addressed question answer forums with two main categories of algorithms. In some of the approaches, models and methods are not directly applied to find experts but rather to find similar and related items. One of such directions is feed distillation that related blogs to a query are retrieved. In the first approach, resources associated with certain queries are identified and contribution of people in those resources are calculated.
In Learning Layers project, experts can increase trust in the network of learners. In other words, learners can find an answer to a question via experts in specific domains. Experts can offer reliable learning materials. Moreover, we can identify communities in networks of learners by employing Overlapping Community Detection (OCD) Service. To clarify the problem, consider a toy example scenario for such a service. As one can observe in Figure 1, users with direct connections toward each other are shown by double-line edges and relationships of users with events such as Build Stuff or How To Team are denoted by single-line edges. Here, users 5, 6 and 7 are both attending in teaming and building events, therefore they have information of both domains. In fact, they are overlapping among the communities of people who attend these two classes. An overlapping community detection algorithm identifies these overlapping members between these two clusters. Moreover, expert 1 and expert 2 have expertise in Build Stuff and How To Team domains that are identified by an expert identification algorithm. This example scenario indicates that expert identification is entangled with overlapping communities of a network. Hence, we proposed overlapping community-aware ranking algorithms to the case of expert identification [7].
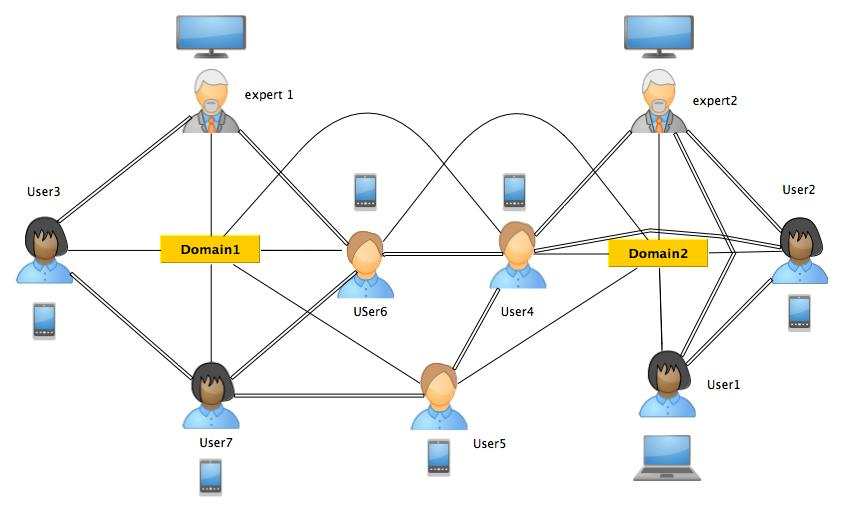
One point regarding expert identification in Learning Layers is the consideration of learners’ network structure as Question-Answer forums which is currently the main platform for finding the intended answer and expertise. Structural–based ranking algorithms and expert identification based on HITS and PageRank can handle networks with explicit links. Our proposed community-aware ranking algorithms belong to this category and the effect of community structures are assimilated with ranking algorithms [7]. We proposed two novel community-aware ranking algorithms, which are extension to PageRank and HITS . The idea is that internal and overlapping nodes carry more relevant information for the community than nodes which are outside of the community. In fact, community-aware HITS considers overlapping community dimension in its hub and authority updating rules. As for community-aware PageRank, random walker would bias its walk toward the nodes inside and on the borders of the community, therefore it avoid paths which leads to the outside of the community [7].
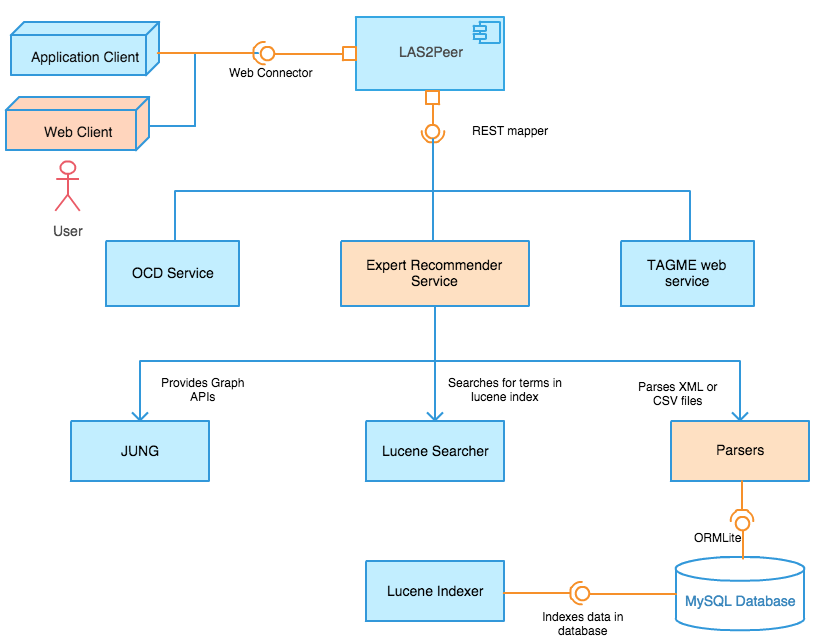
EIS integrates several smaller components in order to provide its full functionalities. It mainly integrates parsers, text processing utilities, indexer, searcher and scoring algorithms. Scoring algorithms are mainly graph-based algorithms such as community-aware ranking algorithms to assign expert values to users. EIS has RESTful endpoints that can be accessed by any application client. EIS service also supports some principal functionalities. Firstly, it provides several expert identification algorithms together with information retrieval evaluation measures. Moreover, it provides some sort of visualization of expertise information. Alongside, some non-functional requirements are also fulfilled. The framework is mainly implemented with las2peer which can be easily integrated with question answer forums. Additionally, EIS is extendable and further algorithms can be integrated with the framework. Figure 2 indicates the expert identification service together with other services and libraries.
Use Cases and Tool Support
Currently EIS service is integrated with Social Semantic Server (SSS). SSS sends query related to a learner to EIS and EIS applies one of its algorithms and returns the list of experts to SSS. EIS can be integrated with other applications and services to support informal workplace learning. For instance, Requirements Bazaar can invoke EIS to find the group of expert users that can fulfill the requirements posted by learners or end users.
Research Results and Impact
Expert Identification as a Restful Web service
SSS requires a service to discover and identify experts to be recommended to novices and overlapping community members. In healthcare and construction clusters, experts play important roles for solving the problems which amateurs face, also scaling up the borders of communities and cascades of information. Correspondingly, EIS is developed to support the big Learning Layers community by identifying experts and ranking of expertise level of people. This service follows a RESTful design, is implemented with las2peer and compliant with a peer-to-peer architecture. Currently two types of algorithms are supported in the developed framework which are link analysis approaches and language models. Link analysis methods only consider the structure and interaction of the network. On the other end, language models consider the content [7].
Precision and Relevancy of Community-Aware Expert Identification Approaches
We evaluated the proposed algorithms with measures including Mean Average Precision (MAP), Mean Recall, mean Normalized Discounted Cumulative Gain (NDCG) and Mean Reciprocal Rank (MRR). MAP and Mean Recall determine the precision of the returned experts and mean NDCG and MRR mostly measure how relevant are the returned results. We applied the algorithms on several data sets including Nature, computer science and Fitness forum. At the beginning, most of the algorithms face the cold start problem. Evaluation results indicated better performance of community-aware ranking algorithms over the period of times [7].
Correlation of Expert Identification Approaches
To observe how similar algorithms behave, Spearman correlation among algorithms is computed. Results indicate that the correlation among the algorithms depends also on the network of users and the structure of the data set. In general, community-aware ranking algorithms based on HITS had high correlation with expert identification based on HITS and community-aware ranking algorithm based on PageRank had high correlation with original PageRank Algorithm [7]. In year 4, similar to expert identification, we applied the community dimension on other application domains such as temporal and signed networks. We employed community features to predict how different communities evolve over time and to predict their future [8]. Moreover, the impact of overlapping communities on signed networks is also investigated [9] [10]. One can observe the positive effect of community information on both temporal and trust networks which is similar to its improved effect on expert identification task.
Evaluation of Expert Identification Service
To gain a better understanding of EIS, we invited 16 students studying computer science to evaluate the framework with some pre-designed tasks. Tasks comprise playing around with the Web client, selecting some specific data sets, finding experts with different algorithms and filling an online evaluation feedback form. After recommendation of experts, users were asked to go through the contents related to the experts. Moreover, users were free to choose different algorithms from the setting panel and to adjust the parameters. Evaluation results revealed positive overall feedback regarding the importance of the EIS. In other words, we learned about the usefulness of EIS for the informal learning workplaces. For instance, all users agreed with the question like “They use such an expert identification system if they need an expert in an organization”. Moreover, from the question “Related posts of the experts helped you decide on the relevance of the expert”, we figured out showing related posts of experts to users may help them to judge regarding the expertise level and the relevance.
Material
Further reading
Links
Developers and Collaborators
- Mohsen Shahriari
- Sathvik Parekodi
- Ralf Klamma
References
- L. Chen and R. Nayak, “Expertise Analysis in a Question Answer Portal for Author Ranking,” in Proceedings of the 2008 IEEE/WIC/ACM International Conference on Web Intelligence and Intelligent Agent Technology - Volume 01, Washington, DC, USA, 2008, pp. 134–140 [Online]. Available at: http://dx.doi.org/10.1109/WIIAT.2008.12 DOI: 10.1109/WIIAT.2008.12
- Zhou Zhao, Lijun Zhang, Xiaofei He, and W. Ng, “Expert Finding for Question Answering via Graph Regularized Matrix Completion,” IEEE Transactions on Knowledge and Data Engineering, vol. 27, no. 4, pp. 993–1004, 2015. DOI: 10.1109/TKDE.2014.2356461
- Z. Ji, F. Xu, B. Wang, and B. He, “Question-answer Topic Model for Question Retrieval in Community Question Answering,” in Proceedings of the 21st ACM International Conference on Information and Knowledge Management, New York, NY, USA, 2012, pp. 2471–2474 [Online]. Available at: http://doi.acm.org/10.1145/2396761.2398669 DOI: 10.1145/2396761.2398669
- T. Hao and E. Agichtein, “Finding similar questions in collaborative question answering archives: toward bootstrapping-based equivalent pattern learning,” Information Retrieval, vol. 15, no. 3-4, pp. 332–353, 2012 [Online]. Available at: http://dx.doi.org/10.1007/s10791-012-9188-x DOI: 10.1007/s10791-012-9188-x
- C. Macdonald and I. Ounis, “Voting for candidates: adapting data fusion techniques for an expert search task,” in Proceedings of the 15th ACM international conference on Information and knowledge management, 2006, pp. 387–396.
- A. Bozzon, M. Brambilla, S. Ceri, M. Silvestri, and G. Vesci, “Choosing the right crowd: expert finding in social networks,” in The 16th International Conference on Extending Database Technology, New York, 2013, pp. 637–648. DOI: 10.1145/2452376.2452451
- M. Shahriari, S. Parekodi, and R. Klamma, “Community-aware Ranking Algorithms for Expert Identification in Question-answer Forums,” in Proceedings of the 15th International Conference on Knowledge Technologies and Data-driven Business, 2015, pp. 1–8 [Online]. Available at: http://doi.acm.org/10.1145/2809563.2809592
- M. Shahriari, S. Gunashekar, M. von Domarus, and R. Klamma, “Predictive Analysis of Temporal and Overlapping Community Structures in Social Media,” in Proceedings of the 25th International Conference Companion on World Wide Web, Republic and Canton of Geneva, Switzerland, 2016, pp. 855–860 [Online]. Available at: http://dx.doi.org/10.1145/2872518.2889292 DOI: 10.1145/2872518.2889292
- M. Shahriari, Y. Li, and R. Klamma, “The Significant Effect of Overlapping Community Structures in Signed Social Networks: Accepted as a chapter in Recent Trends in Social Network Analysis and Mining(In publication process),” 2016.
- M. Shahriari, Y. Li, and R. Klamma, “Analysis of Overlapping Communities in Signed Complex Networks,” in International Conference on Knowledge Technologies and Data-driven Business (i-KNOW), 2016.