
Services for Overlapping Community Detection
Purpose
Overlapping community detection (OCD) services support analytic services such as recommender systems to detect overlapping communities. OCD services contain algorithms that identify overlapping community structures among the networks of learners. In Learning Layers, learners constitute a network of interactions based on tagging, rating and commentating the same entity, using the same tag, participating in the same discussion, accessing the same collections or belonging to the same groups. Many research works have approached the topic from different aspects and improved both the complexity and precision of the algorithms; however, these algorithms are sometimes complex and their versatility is not proven on certain applications. Moreover, algorithms are not implemented as Web services so this makes them difficult to be deployed. In Learning Layers, novel structural and context-aware OCD algorithms are implemented as las2peer microservices containing a separate Web connector. This provides the possibility to be integrated with other software packages.
We summarize our major contributions on overlapping community research as follows:
-
We proposed a two-phase OCD algorithm based on two social dynamic named disassortative degree mixing and information diffusion [1]. All of the algorithms, metrics and measures are developed as a generalized and extendable framework [2].
-
We proposed a two-phase OCD algorithm for trust networks based on effective degree and signed information diffusion [3]. This algorithm is named SDMID; it is compared with several baselines [4]. Moreover, we differentiated between roles of inter, overlapping and extra nodes in communities. We built prediction models and indicated the significant roles of overlapping members in social media [5].
-
We proposed content-based OCD algorithms such as CFOCA and TCMA. Moreover, we compared and investigated their dynamics in open source developer communities [6].
-
We mapped overlapping communities over time and predicted them in temporal networks. We could identify significant indicators to predict future of overlapping communities [7].
Description
In recent years, researchers have been interested in identifying the more connected and dense parts of graphs, named communities. There is still no well-established definition of the term community but we consider both a traditional and a more modern one. In the classical understanding, communities are considered components in which internal cluster relationships are dense and the relationships among different components are sparse [8] [9]. In a more modern definition online communities are defined as groups of people or nodes, which interact with each other based on their needs and interests [10] [11] . First research on community detection algorithms just intended to identify a set of disjoint communities. However, today’s online networks constitute of people (or nodes) that belong to more than one community [12]. To clarify overlapping communities, consider the common example of a Zachary Karate club with 78 connections and 34 nodes. Figure 1 [1] indicates the detected overlapping communities in this network [1]. Nodes 2, 14, 3, 20, 9 and 31 are detected as overlapping nodes with different levels of membership degree in this network.
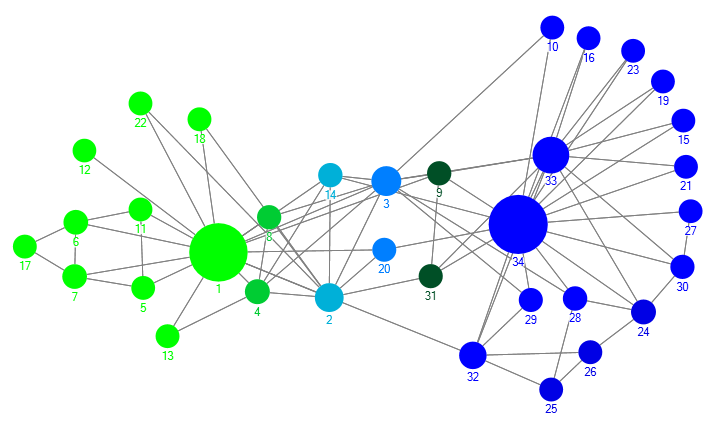
In Learning Layers, Overlapping Community Detection (OCD) algorithms support meaningful learning. As to scale up informal learning across communities of learners, overlapping nodes should be identified. Identifying boundary spanners in learning environments and especially informal learning ecosystems is a significant task because they are effective in expanding the communities and circulating information among different disciplines. Moreover, finding experts in communities of practices highly depends on OCD algorithms. In fact, experts need to be aware of overlapping nodes that can scale-up informal learning across communities of learners. In Layers project, OCD algorithms can play different roles. First, they detect overlapping nodes in order to expand community borders and increase the information flow across communities. Secondly, they enhance knowledge about groups and enable internal tagging to reach a shared understanding. Moreover, identifying hidden relationships among groups of learners contributes to targeted recommendations of experts and learning materials.
There has been a large body of research on overlapping community detection; however, these algorithms are rather complex. In special environments such as informal learning environments, simple algorithms based on real social dynamics can be more effective. Moreover, algorithms that consider content of communications have higher precision. To this end, a two-phase OCD algorithm based on two social dynamics is proposed. The first phenomenon to identify influential nodes is disassortative degree mixing which shows dissimilarities among neighbors of nodes. The second involved dynamic is information diffusion to assign nodes to communities [1]. In addition, novel context-aware OCD algorithms based on actual post communications in forums are implemented and integrated with OCD service [6]. Furthermore, we innovated a novel algorithm for trust networks and evaluated OCD algorithms in temporal networks [7] [3]. Results indicate that our novel algorithms behave competitively efficient on the test cases.
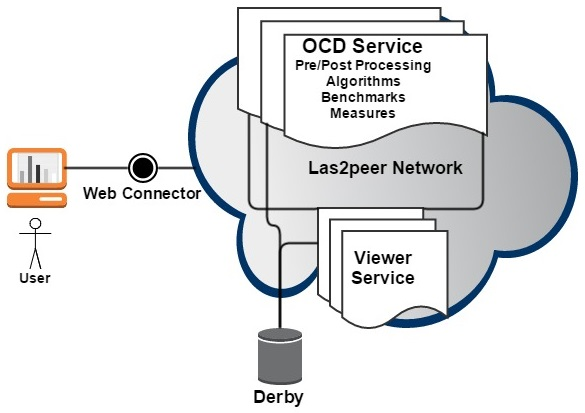
OCD service is named WebOCD which consists of two main services named OCD service and viewer service. The OCD service is responsible to provide core OCD functionalities. These core tasks include running algorithms, metrics and benchmarks. The viewer service visualizes graphs and covers through a Web client. Both services are implemented with las2peer which support a peer to peer architecture. WebOCD framework is visualized in Figure 2 [2]. The WebOCD framework supports three principal functional requirements. First of all, several OCD algorithms are integrated with it. Moreover, various metrics and measures to evaluate the community detection algorithms are implemented and integrated with the framework. Additionally the service is able to visualize the resulting covers. Other non-functional requirements are supported by WebOCD service like having Web client and RESTful design [2]. In the second year of Layers project, WebOCD only supported unsigned networks such as simple networks of learners; however, during the fourth year of the project, content-based algorithms, i.e. CFOCA, TCMA and signed OCD algorithms are implemented and integrated with OCD service [6] [4].
Use Cases and Tool Support
Currently OCD service is invoked by Social Semantic Server (SSS) through REST calls. SSS sends network of learners to OCD. Afterwards, clusters of people are sent back to the SSS. Learners constitute a network of interaction based on tagging, rating and commentating the same entity, using the same tag, participating in the same discussion, accessing the same collections or belonging to the same groups. Expert identification service also invokes algorithms of OCD service to identify experts. In addition, OCD service can be employed by other tools and services. For instance, Requirements Bazaar can identify learners with similar requirements residing in the same community in which developers can better address these groups of people.
Research Results and Impact
Structural-based Overlapping Community Detection Algorithms
We approached overlapping community detection research from different aspects in Learning Layers project. In the second year of the project, we devised a structural algorithm suitable for static networks named DMID. It works based on two social dynamics named disassortative degree mixing and information diffusion. Disassortative degree mixing shows dissimilarity among nodes in a network and information diffusion applies dissemination strategies such as network coordination game on networks. To clarify disassortative degree mixing, one may bring the example of the relation among professors and students in a university. Or the potential connections among higher class with middle or lower class people in societies. In the first phase, a disassortative matrix is induced out of degree difference of nodes and employed to perform a random walk. The random walk computes a disassortative value for each node that indicates how this node differs from its neighbors. Disassortative values are mixed with degree of nodes to identify influential nodes in the network. It is assumed that communities form around influential members or leaders.
In the second phase, dependency of nodes to leaders is computed based on an information diffusion process name network coordination game [1]. Considering binary states for opinions like A and B and equal resistance threshold for all the nodes, contribute to agree to a simple diffusion strategy. A simple example of opinion formation and informed agents can be a new mobile brand. People seeing your brand new mobile might imitate your propensity especially if you have high charismatic character (being an influential member or leader). Thus, people around identified leaders in the first stage, may accept the opinions of the leaders based on their dependency to these set of influential nodes. Membership magnitude of common members to communities (here leaders) can be computed based on the dependency and the time that the synchronization happens with the leaders.
These algorithms were implemented as RESTful Web services together with some other algorithms from the literature to detect community structures in the network of learners and users. We evaluated the proposed algorithm together with the baselines with metrics such as running time, modularity and normalized mutual information. Evaluation results indicate competitive performance of DMID in comparison to the baselines (i.e, CLiZZ, SSK, Link Communities and so on) [1]. In Learning Layers, detection of community structures helps experts to recognize the community borders and thus understand how to expand communities. As real networks are dynamic in nature and evolve over time, therefore we address the evolution of communities in a temporal setting. We applied the implemented algorithms in the project to predict how communities evolve over time.
Overlapping Community Detection Algorithms on Temporal Networks
In the third year of the project, the proposed algorithm DMID and some other baselines are applied to predict the evolution of overlapping communities over time. Overlapping communities are linked to the prediction problem; unfortunately almost all the works neglect an integrative perspective, hence significant features to predict overlapping communities have not been determined. It is significant to identify these properties for communities in Learning Layers project. Thus, we applied the proposed OCD algorithm together with other baselines on dynamic networks including Email, DBLP and Facebook data sets. The properties of some of these algorithms are contrasted against each other in terms of number and size of communities and frequencies of overlapping members. DMID detects almost smaller number of communities, in fact bigger community sizes. To constitute an analysis over time, the communities are mapped over time through Group Evolution Discovery (GED) technique and events happening to each community are identified. They comprise dissolve, merge, split and survive. We applied several community level features such as size, density, cohesion and so on to predict the fate of communities. In this regard, prediction models using logistic regression classifier are implemented. Results indicate that size of communities is a distinctive indicator to predict the fate of communities. Besides, DMID generates the highest community prediction accuracies among its competitors [7].
Content-Based Overlapping Community Detection Algorithms
In year four of the project, we improved the overlapping community detection algorithms via shifting the research line toward devising context-aware algorithms. In other words, context of communities generated by users is combined with structural information of the network to devise better algorithms. In real life, people may initiate new connections or message each other while they have some thoughts, innovation and talks to share and communicate. Hence, conversations (posts) and how people tend to discuss together may cause communities to form and hold people tightly together. Two contextualized algorithms working based on Term Frequency and Inverse Document Frequency (TF-IDF) of posts are devised. In the first algorithm, posts related to each user are extracted and converted to TF-IDF vectors. Afterwards, by defining an optimization problem together with K-means clustering algorithm, communities are detected. Overlapping members are identified by applying a threshold value based on node distances to the centroids; it is named Cost Function Optimization Clustering Algorithm (CFOCA).
The second algorithm works by considering each term as a cluster and merging of features based on an overlapping threshold; this algorithm is called Term Community Merging Algorithm (TCMA). Moreover, weights induced by implicit number of communications among members are combined with content weights. The proposed content-based algorithms are compared with several baselines (i.e. SLPA, DMID, SSK and CLiZZ). Results indicate that CFOCA and TCMA competitively detect communities. To evaluate these algorithms, they are compared and contrasted regarding number of overlapping nodes, modularity and average community sizes [6]. The algorithms are integrated with WebOCD framework and evaluated on open source software project data sets.
Overlapping Community Detection Algorithms on Trust Networks
To consider trust in Learning Layers project, we considered networks with both positive and negative connections. Positive edges are sign of trust and negative links indicate distrust. To pursue OCD algorithms in signed graphs, we extended DMID to the case of trust networks; we named it SDMID. In this case computation of disassortative matrix are extended to consider negative connections. Moreover, an extended information diffusion process is considered by considering negative links. In the fourth year, we compared SDMID with two other OCD algorithms including SPM and MEA. Modularity, running time, Normalized Mutual Information, number of overlapping nodes, number and size of communities are computed and compared for these algorithms. Results indicate better performance of SDMID in case of trust networks [3] [4] [5].
Research has proposed a large body of approaches to detect overlapping communities; however, significance of overlapping members in social networks has not been investigated. To pursue this goal in Learning Layers project, we considered a prediction model using logistic regression and several other classifiers in order to identify importance of overlapping members. We considered links incoming to a node and outgoing from a node into three different categories of intra, extra and overlapping nodes. We evaluated the results of these categories through prediction accuracy, MAE and RMSE metrics. Results indicate that overlapping nodes have high degree of importance in the network [3] [5].
Evaluation of OCD Service Functionalities
To gain a better understanding of the main functionalities of WebOCD service, some master and PhD students were invited to perform some specific tasks. After we explained the main functionalities and elements in OCD service, they were asked to accomplish several analytic tasks regarding the service and algorithms. After doing the evaluation, some Web-based questionnaires were handed out among the participants and they were supposed to rate the OCD service with 5 point scales. The online evaluation revealed that OCD service obtained satisfactory feedback and the participants are willing to employ the service for their needs in future [2].
Taking a look at Table 1 [2], the feedback is very positive throughout. In other words, all of the statements have received mean values above 4.0. Furthermore, the overall impression of the system was positive. The only statement not obtaining a clearly positive rating was statement number five about useful error messages which is 3.0 for mean and median and 0 for standard deviation. Here several respondents stated that they neither agree nor disagree.

Material
Further reading:
Links
Developers and Collaborators
- Mohsen Shahriari
- Sebastian Krott
- Sabrina Haefele
- Ying Li
- Ralf Klamma
References
- M. Shahriari, S. Krott, and R. Klamma, “Disassortative Degree Mixing and Information Diffusion for Overlapping Community Detection in Social Networks (DMID),” in Proceedings of the 24th International Conference on World Wide Web, 2015, pp. 1369–1374. DOI: 10.1145/2740908.2741696
- M. Shahriari, S. Krott, and R. Klamma, “WebOCD: A RESTful Web-based Overlapping Community Detection Framework,” in Proceedings of the 15th International Conference on Knowledge Technologies and Data-driven Business, 2015.
- M. Shahriari and R. Klamma, “Signed Social Networks: Link Prediction and Overlapping Community Detection,” in The 2015 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining (ASONAM), Paris, France, 2015. DOI: 10.1145/2808797.2810250
- M. Shahriari, Y. Li, and R. Klamma, “Analysis of Overlapping Communities in Signed Complex Networks,” in International Conference on Knowledge Technologies and Data-driven Business (i-KNOW), 2016.
- M. Shahriari, Y. Li, and R. Klamma, “The Significant Effect of Overlapping Community Structures in Signed Social Networks: Accepted as a chapter in Recent Trends in Social Network Analysis and Mining(In publication process),” 2016.
- M. Shahriari, S. Haefele, and R. Klamma, “Contextualized versus Structural Overlapping Communities in Social Media,” in International Conference on Knowledge Technologies and Data-driven Business (i-KNOW), 2016.
- M. Shahriari, S. Gunashekar, M. von Domarus, and R. Klamma, “Predictive Analysis of Temporal and Overlapping Community Structures in Social Media,” in Proceedings of the 25th International Conference Companion on World Wide Web, Republic and Canton of Geneva, Switzerland, 2016, pp. 855–860 [Online]. Available at: http://dx.doi.org/10.1145/2872518.2889292 DOI: 10.1145/2872518.2889292
- M. Girvan and Newman, Mark E. J., “Community structure in social and biological networks,” Proceedings of the National Academy of Sciences, vol. 99, no. 12, pp. 7821–7826, 2002. DOI: 10.1073/pnas.122653799
- B. Wellman, “The network community: An introduction,” Networks in the global village. Life in contemporary communities, pp. 1–47, 1999.
- L. Backstrom, D. Huttenlocher, J. M. Kleinberg, and X. Lan, “Group Formation in Large Social Networks: Membership, Growth, and Evolution,” in Proceedings of the 12th ACM SIGKDD international conference on Knowledge discovery and data mining - KDD ’06, 2006, pp. 44–54 [Online]. Available at: http://doi.acm.org/10.1145/1150402.1150412 DOI: 10.1145/1150402.1150412
- J. Preece, Online Communities: Designing Usability and Supporting Socialbility. New York, NY,USA: John Wiley & Sons, Inc, 2000.
- I. Derényi, G. Palla, and T. Vicsek, “Clique Percolation in Random Networks,” Physical Review Letters, vol. 94, no. 16, p. 160202, 2005 [Online]. Available at: http://link.aps.org/doi/10.1103/PhysRevLett.94.160202 DOI: 10.1103/PhysRevLett.94.160202