
Resource Recommendation Services
Purpose
Resource recommendation services support users in finding resources in a specific learning situation. This is achieved via analyzing users’ past interactions with learning resources using Collaborative Filtering (CF) algorithms [1]. In Layers, we extended CF-based algorithms with integrating various context dimensions such as time, location and semantic cues (e.g., resource categories). In this respect, we have not only evaluated the influence of these context dimensions on the recommendation quality but also proposed a novel resource recommendation approaches termed SUSTAIN, which utilizes a theory of human category learning.
In summary, the following main contributions are provided:
-
We integrated various context dimensions into the recommendation process (e.g., semantic, location and time) [2] [3]
-
We proposed a novel cognitive-inspired resource recommendation algorithm (i.e, SUSTAIN) [4] [5]
-
We provide recommendations of learning resources via the Social Semantic Server (SSS) for various Layers tools (e.g., Bits and Pieces and KnowBrain)
-
We extended these approaches for trust-based recommendations [6] and multi-domain recommendations [7] [8].
Description
We developed a set of resource recommender services that not only utilize formal metadata (e.g., semantic, location and time context) but also user provided metadata (e.g., tags). The task of resource recommendation emerges when the user needs assistance or further information in a specific learning situation. The output of the task is the suggestion of a resource (e.g., a learning material, discussion, Q/A, etc.), which is described by its metadata (e.g., title, description, etc.) that should be of interest for a user in a specific learning situation (current context). Also, the user is described by metadata in his user profile (e.g., age or interests). Interactions between users and resources can be either explicit (e.g., rating the resource) or implicit (e.g., viewing a resource or marking a resource as favourite). Additional information can be derived from social-network and location-based data, as interactions can also happen either between two users or between a user and a location. In the latter case, the interactions are mostly implicit (e.g., a user likes something from another user or a user visits a location).
Apart from that, utilizing information about location and peers “similar to me” (i.e., users with similar expertise, skills, interests, etc.) is important to aggregate trust and engage new connections among professionals. Similarly, recommended resources can work as indices of shared experience. By providing cues in the learning process, they can help to reinstate that shared experience and contribute to joint meaning making. In that case, temporality and physical context play an important role.
Considering the current context of the user (e.g., implicitly interacting with a resource on a given location), we developed multiple approaches based on Collaborative Filtering to calculate relevant resource recommendations. Collaborative Filtering [1] aims at finding users that have a similar taste as the current user (e.g., have interacted with the same resources in the past) and suggesting the resources these users have interacted with and that are new to the current user. The underlying assumption of Collaborative Filtering is that if “user a” has the same opinion on an issue as “user b”, “user a” will likely also have the opinion of “user b” on a different issue. In order to calculate the similarity between users we defined different similarity features, which leverage the available data on different formality levels (e.g., using tagging, social network or location-based data).
Summing up, our contributions are three-fold:
-
(i), we provide a wide-range of context-aware recommendation algorithms [2] [3] [4] that utilize various context dimensions such as social-semantic cues, time and location
-
(ii), we propose a novel resource recommendation algorithm termed SUSTAIN, which utilizes a theory of human category learning [5] [9]
-
(iii), we provide recommendations of learning resources via the SSS for various Layers tools (e.g., Bits and Pieces and KnowBrain)
Use Cases and Tool Support
Our resource recommendation services are implemented in our open-source SocRec [10] and TagRec (see Tag recommendation services) frameworks, which can be accessed via the SSS. Thus, the services can be easily accessed via various Layers tools.
For example, KnowBrain and the Bits & Pieces / DiscussionTool use the resource recommendation services to suggest existing Q&A threads when the user attempts to create new threads. In Bits and Pieces and Living Documents, our resource recommendation services are used to suggest learning resources to the users that are new to them.
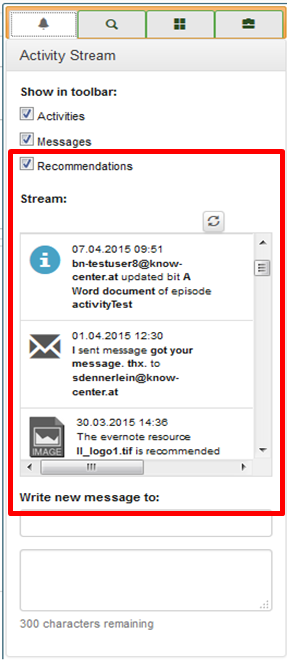
To illustrate this, Figure 1 shows the activity stream of Bits and Pieces, in which recommendations of potentially interesting Bits are shown.
Another potential use case of a context-aware recommender systems is visualized in Figure 2. Here, beacons are used to track the locations of users via their smartphones [3]. Thus, this information can not only be used to gather movement data of users but also to determine the exact location-context of a user when calculating recommendations.
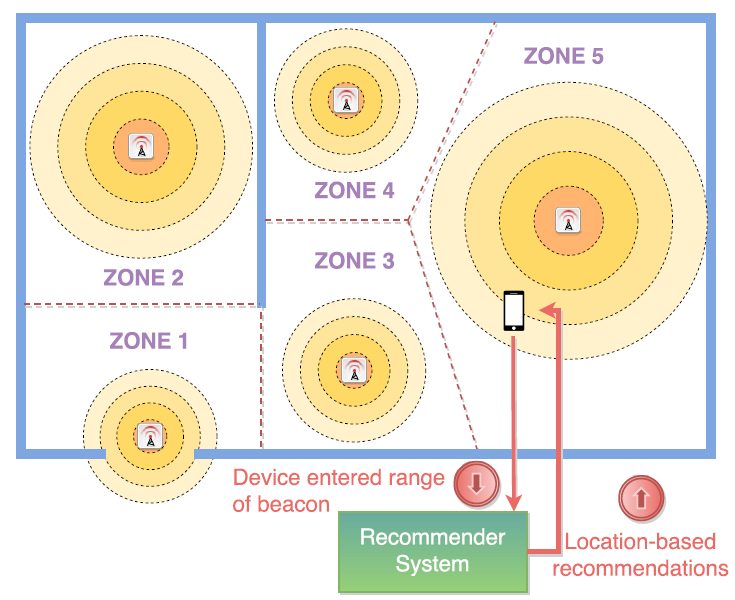
We believe that such location-aware recommendations could be of high use to recommend physical artefacts to users in tools such as AchSo!.
Research Results and Impact
In this section, we describe our research results in the area of resource recommendations. Here, we focus on our novel cognitive-inspired and context-aware algorithms. Please also have a look at the impact section (see Link) describing how learners are guided and supported via resource recommendations.
Mimicking Attention-Interpretation Dynamics for Recommendations
In order to account for the semantic context of a learner, we were working on a novel hybrid resource recommender strategy to recommend resources to users [5] [9]. This work was motivated by the fact that classic Collaborative Filtering (CF) [1], which is typically used for resource recommendations, is not enough to support informal learning settings. Being based on Social Network Analysis (SNA), CF treats users as being just another entity such as resources or tags, and, thus, neglects semantic and non-linear user-resource dynamics, which shape attention and interpretation. CF thereby neglects knowledge creation processes as stipulated in the “knowledge creation metaphor” of learning.
We modelled these dynamics using a connectionist approach towards human categorization with interconnected input, hidden and output units that map inputs (e.g., topics of resources) to outputs (e.g., decision to take or leave a resource). Therefore, we used the self-supervising model of human category learning SUSTAIN [11], which can be trained on a user’s history (i.e., collected resources) to achieve a user-specific semantic network consisting of a set of topic clusters describing the interests of the user. This network can then be applied to a set of candidate resources in order to determine the usefulness of these resources for recommendations. These connectionist models are a natural extension of our attempt to model emergence of meaning by means of pattern learning algorithms.
We determined these candidate resources using user-based Collaborative Filtering (CFu) to generate a pool of resources based on the interests of like-minded users. Thus, our approach, SUSTAIN+CFu, can be seen as a hybrid approach that “further personalizes” CFu using a model of human category learning. We evaluated our approach on three datasets gathered from the social bookmarking systems BibSonomy, CiteULike and Delicious to answer the question if SUSTAIN can really improve the accuracy of CFu. The results are visualized in Table 1.
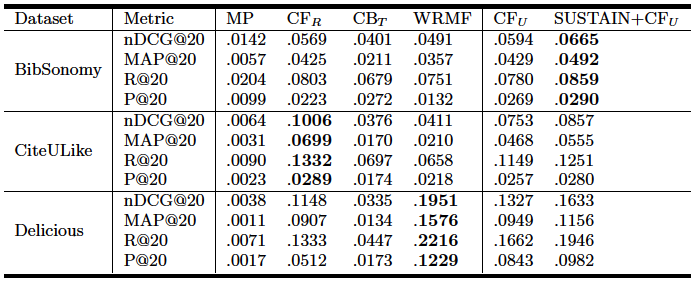
The results show that SUSTAIN improves CFu in the case of all three datasets. Furthermore, our results also indicate that SUSTAIN+CFu successfully competes with a computationally much more expensive Matrix Factorization [12] variant. Apart from that, our approach has also been evaluated in various TEL settings [13].
Context-Aware Recommendations of Resources
In the course of the Layers project, we worked on various resource recommendation services, which exploit different context dimensions, namely the semantic, location and temporal context.
As we incoporated the semantic context of a learner via our SUSTAIN approach, we focus on the location and temporal contexts in the reaminder of this section.
Supporting informal learning by considering the location context of items (e.g., physical artefacts) is especially important when dealing with new users with less or no data at all. Namely, most existing recommender systems rely on item interactions (i.e., artefact interactions) as the main information source for prediction. For instance, the state-of-the-art Matrix Factorization methods [12] are able to provide reasonable results when a minimum number of user-item interactions are available. However, these methods fail in “extreme” cold-start settings with no item interaction data available at all. In such cases, non-personalized recommendations are usually provided.
In [3], we simulated a scenario where movement data (i.e., check-ins) from the location-based FourSquare dataset is used to generate recommendations for “extreme” cold start users (see also Figure 1). Our results reveal that the location-based approaches outperform the standard popularity baseline for handling users with no item interaction data available. We also suggested considering the ever-increasing trend of providing mobile applications to help users navigate through different kinds of public areas, such as scientific conferences, or the workplace. The reason for this is that these applications can easily acquire a user’s location information using indoor positioning systems to automatically collect location-based item interaction data with no need for any explicit user action (e.g., a click).
Regarding the context of time, we proposed a resource recommendation approach termed CIRTT, which integrates the BLL equation of the cognitive architecture ACT-R [14] in order to account for the effect of time-dependent decay [4]. We showed that this approach is not only able
Resource Recommendations in Course of the AFEL Project
After Layers and in course of the H2020 project AFEL (Analytics for Everyday Learning) [15], we applied our algorithms for resource recommendations in social learning environments [16]. In this respect, we also researched on the value of user pre-filtering to enhance Collaborative Filtering [17] and on providing diversity-aware recommendation on Twitter to mitigate confirmation bias [18].
Material
Links
-
SocRec framework: Link
-
Know-Center’s ScaR framework: Link
-
Impact section describing how learners are guided and supported via resource recommendations: Link
-
Slides about social recommender systems presented at WWW’2014 in Seoul, Korea:
- Slides about cognitive-inspired resource recommendations presented at WWW’2015 in Florence, Italy:
Developers and Contributors
Dominik Kowald, Emanuel Lacic, Paul Seitlinger, Tobias Ley, Elisabeth Lex
References
- J. B. Schafer, D. Frankowski, J. Herlocker, and S. Sen, “Collaborative filtering recommender systems,” in The adaptive web, Springer, 2007, pp. 291–324.
- E. Lacic, D. Kowald, L. Eberhard, C. Trattner, D. Parra, and L. B. Marinho, “Utilizing online social network and location-based data to recommend products and categories in online marketplaces,” in Mining, Modeling, and Recommending’Things’ in Social Media, Springer, 2015, pp. 96–115.
- E. Lacic, D. Kowald, M. Traub, G. Luzhnica, J. Simon, and E. Lex, “Tackling Cold-Start Users in Recommender Systems with Indoor Positioning Systems,” in Proceedings of the 9th International Conference on Recommender Systems, 2015.
- E. Lacic, D. Kowald, P. Seitlinger, C. Trattner, and D. Parra, “Recommending Items in Social Tagging Systems Using Tag and Time Information,” in Proceedings of the 25th ACM conference on Hypertext and social media, 2014.
- P. Seitlinger, D. Kowald, S. Kopeinik, I. Hasani-Mavriqi, E. Lex, and T. Ley, “Attention Please! A Hybrid Resource Recommender Mimicking Attention-Interpretation Dynamics,” in Proceedings of the 24th International Conference on World Wide Web, 2015, pp. 339–345.
- T. Duricic, E. Lacic, D. Kowald, and E. Lex, “Trust-Based Collaborative Filtering: Tackling the Cold Start Problem Using Regular Equivalence,” arXiv preprint arXiv:1807.06839 - to be published at RecSys’2018, 2018.
- E. Lacic, D. Kowald, and E. Lex, “Tailoring Recommendations for a Multi-Domain Environment,” 2017.
- E. Lacic, D. Kowald, M. Reiter-Haas, V. Slawicek, and E. Lex, “Beyond Accuracy Optimization: On the Value of Item Embeddings for Student Job Recommendations,” arXiv preprint arXiv:1711.07762 - published in WSDM2018 workshop proceedings., 2017.
- S. Kopeinik, D. Kowald, I. Hasani-Mavriqi, and E. Lex, “Improving Collaborative Filtering Using a Cognitive Model of Human Category Learning,” The Journal of Web Science, vol. 2, no. 1, 2016.
- E. Lacic, D. Kowald, and C. Trattner, “Socrecm: A scalable social recommender engine for online marketplaces,” in Proceedings of the 25th ACM conference on Hypertext and social media, 2014, pp. 308–310.
- B. C. Love, D. L. Medin, and T. M. Gureckis, “SUSTAIN: a network model of category learning.,” Psychological review, vol. 111, no. 2, p. 309, 2004.
- Y. Koren, R. Bell, C. Volinsky, and others, “Matrix factorization techniques for recommender systems,” Computer, vol. 42, no. 8, pp. 30–37, 2009.
- S. Kopeinik, D. Kowald, and E. Lex, “Which Algorithms Suit Which Learning Environments? A Comparative Study of Recommender Systems in TEL,” in European Conference on Technology Enhanced Learning, 2016, pp. 124–138.
- J. R. Anderson, D. Bothell, M. D. Byrne, S. Douglass, C. Lebiere, and Y. Qin, “An integrated theory of the mind.,” Psychological review, vol. 111, no. 4, p. 1036, 2004.
- M. d’Aquin, D. Kowald, A. Fessl, E. Lex, and S. Thalmann, “AFEL-Analytics for Everyday Learning,” in Companion of the The Web Conference 2018 on The Web Conference 2018, 2018, pp. 439–440.
- D. Kowald, E. Lacic, D. Theiler, and E. Lex, “AFEL-REC: A Recommender System for Providing Learning Resource Recommendations in Social Learning Environments,” arXiv preprint arXiv:1808.04603 - to be published at CIKM’2018 workshop proceedings, 2018.
- E. Lacic, D. Kowald, and E. Lex, “Neighborhood Troubles: On the Value of User Pre-Filtering To Speed Up and Enhance Recommendations,” arXiv preprint arXiv:1808.06417 - to be published at CIKM’2018 workshop proceedings, 2018.
- E. Lex, M. Wagner, and D. Kowald, “Mitigating Confirmation Bias on Twitter by Recommending Opposing Views,” arXiv preprint arXiv:1809.03901 - presented at European Computational Social Science Symposium, 2018.