
Semantic Video Annotation (SeViAnno) Services
Purpose
SeViAnno [1] [2] [3] [4] [5] is a collection of annotation services which allow several types of semantic annotations, i.e. free-text, Place, Object, Agent, Concept, and Event for digital artifacts. SeViAnno services have been put to use for annotation on videos and 3D objects.
Description
SeViAnno services were developed as an integrated part of the Tethys, the cloud solution preceding the Layers Box. Starting from the SeViAnno application and its mobile version, AnViAnno, a dedicated Layers mobile version was developed, called Ach so!, with the purpose to support mobile video annotation.
In the basic SeViAnno use-case, a video can be uploaded using dedicated services for video transcoding, such as Cloud Video Transcoder. The video is transcoded using scalable services which can deal with multiple videos at the same time and stored in a shared repository. Streaming services are also available for the videos. Several types of semantic annotations can be added, keeping into account video time points/time interval information, provided by dedicated services for metadata.
The SeViAnno services have been used as well for the annotation of 3D objects in the Web browser. As depicted in Figure 1, Web-based collaborative learning environments enable groups of learners to negotiate meaning around shared digital artefacts, e.g. by annotating them collaboratively [4]. This particularly applies for complex digital artefacts such as multimedia or 3D objects and is mostly achieved by using metadata description standards, understandable to both user and machines for queries, context detection and retrieving relevant details. Following the rapid prototyping approaches used in the Layers project (e.g., DevOpsUse methodology, the Layers Box), virtual study spaces can be constructed efficiently by using lightweight Web technologies on the server and the browser side. The collaboration on the 3D objects is realized on the client side using the Yjs framework.
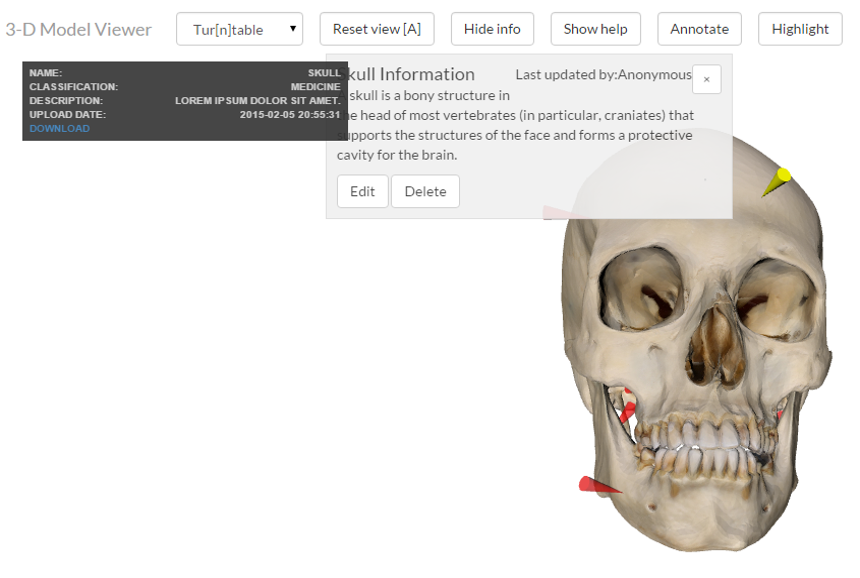
Figure 1 - Collaborative Annotation of 3D Objects
In the scope of the video annotation services, client-side support using Yjs was developed for the collaborative drawing on videos [5], which enables a richer interaction with videos and a closer possible integration with mobile tools such as Ach so!.
Use Cases and Tool Support
- SeViAnno provides annotation las2peer services, using a Non SQL database for storing the annotations as a graph
- Addresses the contextualization and adaptation in informal learning settings. An example for this use case is the usage of adaptive strategies for presenting personalized video segments to users based on their user profile based on metadata-enhanced and annotated videos from within a Layers Box [6].
Research Results & Impact
Material
Links
Developers and Contributors
SeViAnno was developed initially within the context of the German Science Foundation Cluster of Excellence Ultra High Speed Mobile Information and Communication (UMIC; http://www.umic.rwth-aachen.de) and evaluated in the context of a cultural heritage setting.
- Petŕu Nicolaescu
- István Koren
- Georgios Toubekis
- Dominik Renzel
- Merja Bauters
- Adam Brunnmeier
- Dominik Studer
- Kevin Jahns
References
- D. Kovachev, Y. Cao, and R. Klamma, “Building mobile multimedia services: a hybrid cloud computing approach,” Multimedia Tools Appl., vol. 70, no. 2, pp. 977–1005, 2014 [Online]. Available at: http://dx.doi.org/10.1007/s11042-012-1100-6 DOI: 10.1007/s11042-012-1100-6
- P. Nicolaescu and R. Klamma, “SeViAnno 2.0: Web-enabled collaborative semantic video annotation beyond the obvious,” in 12th International Workshop on Content-Based Multimedia Indexing, CBMI 2014, Klagenfurt, Austria, June 18-20, 2014, 2014, pp. 1–6 [Online]. Available at: http://dx.doi.org/10.1109/CBMI.2014.6849833 DOI: 10.1109/CBMI.2014.6849833
- P. Nicolaescu, D. Renzel, I. Koren, R. Klamma, J. Purma, and M. Bauters, “A Community Information System for Ubiquitous Informal Learning Support,” in 2014 IEEE 14th International Conference on Advanced Learning Technologies (ICALT), Los Alamitos, CA, USA, 2014, pp. 138–140. DOI: 10.1109/ICALT.2014.48
- P. Nicolaescu, G. Toubekis, and R. Klamma, “A Microservice Approach for Near Real-Time Collaborative 3D Objects Annotation on the Web,” in Proceedings of the 14th International Conference on Web-based Learning (ICWL), Guangzhou, China, November 5-8, 2015, 2015, pp. 187–196. DOI: 10.1007/978-3-319-25515-6_17
- I. Koren, P. Nicolaescu, and R. Klamma, “Collaborative Drawing Annotations on Web Videos,” in Proceedings of the 15th International Conference on Engineering the Web in the Big Data Era - Volume 9114, New York, NY, USA, 2015, pp. 671–674 [Online]. Available at: http://dx.doi.org/10.1007/978-3-319-19890-3_54 DOI: 10.1007/978-3-319-19890-3_54
- M. Kravcik, P. Nicolaescu, A. Siddiqui, and R. Klamma, “Adaptive Video Techniques for Informal Learning Support in Workplace Environments,” in Proceedings of the 9th International Workshop on Social and Personal Computing for Web-Supported Learning Communities, Rome, Italy, October 26-29, 2016.